2021/03/01
自動ジョイント配置を目指して~Deep Learning奮闘記~

こんにちは、BACKBONEの中川です。
2010年代より、
Deep Learningが猛烈な勢いで世の中の技術を刷新し続けています。
Deep Learningは汎用技術と評される通り、
画像認識・音声認識・自然言語処理など、あらゆる分野で活用されており、
近年、CG分野での研究結果も数多く報告されています。
私がCG業界への就職を希望する学生時代に、
個人的にDeep Learningの隆盛に興味を持ちました。
始めに興味を持ったきっかけは、
線画の自動彩色サービスPetalica Paint(当時の名称はPaintsChainer)だったと思います。
とても身近な分野でもDeep Learningが応用されるようになるにつれ、
自身もこの技術をリグ工程で生かしたいと考えるようになり、勉強を始めました。
当時はまだリグの知識も技術も未熟であり、
Deep Learningも勉強したてでしたので至らぬ点の多い結果となりましたが、
この時の奮闘を記事としてまとめてみます。
今後、このときの結果に対する課題を現在の視点から捕えなおし、
改善するさまも共有できればと思っています。
※詳細な技術解説などは省いておりますので、あくまで奮闘記としてお読みいただければ幸いです。
なお、この記事では「モデル」という言葉を用いる際は、
3DCGにおけるモデルではなく、Deep Learningにおけるモデルを指しますのでご注意ください。
3DCGにおけるモデルを指す際は「メッシュ」と記載します。
0. はじめに
今回は、【人型メッシュのジョイント位置を自動推定する】ツールの作成を目指します。
ボタンを押せば、首や肩などのジョイントが自動で配置されるようなイメージです。
メッシュの体格によらず、またAスタンスであろうがTスタンスであろうが、
適切な位置に配置されると嬉しいですね。
まずは第一ステップとして、およその位置に配置できればよいものとし、
奥行きを無視して正面から見た2次元位置の推定を目標にします。
今回の検証過程を、以下のフローに分けて記載します。
1.モデルの概要
2.教師データの作成
3.テストデータでの検証
なお、今回の検証ではDeep LearningのフレームワークとしてTensorFlowを利用しましたが、
以下では特定のフレームワークに依存しない範囲で記載しています。
1. モデルの概要
そもそも「モデル」とは何か?
Deep Learningにおいてどういう位置づけなのか?
まずは、手書きの数字を識別するモデルで具体的に例示したいと思います。
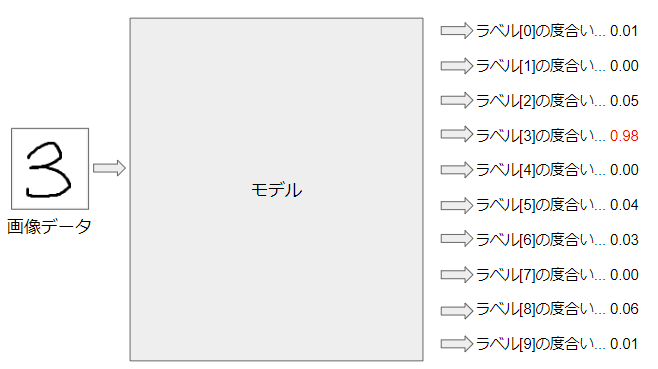
これは、画像データを入力すると、それがどの数字であるかを出力するモデルです。
「ラベル」とは、入力されたデータが何を表すかを意味する情報です。
一般に、0~1の値を取り、正解に近いほど1に近くなります。
この場合、ラベル[3]である度合いが強いため、
「この画像は[3]である」と識別している、ということになります。
同様にメッシュからジョイント位置を推定するモデルを作りたい場合は、
以下のような流れにすればよさそうです。

メッシュデータを入力すると、
各ジョイントのワールド位置を出力するようなモデルを構築すればよい、ということになります。
このように、どのような形式であれ入力に対する出力結果を計算するのが、
Deep Learningにおける「モデル」です。
それでは、具体的にモデルの中身を設計します。
今回のモデルを設計するにあたり重要なのは、
どのような体格や姿勢であっても適切な位置にジョイントを配置してほしい、という点です。
たとえば、肩の位置を推定する際は、
入力データから「このあたりが肩らしい」という特徴を抽出する必要があります。
一般に画像認識モデルなどにおいて、位置や大きさに依存せず特徴を抽出する目的で、
CNN(畳み込みニューラルネットワーク)層とmax pooling層の組み合わせが頻繁に用いられています。
参考:Machine Learning Crash Course _ convolutional-neural-network
今回もこの組み合わせを用いてモデルを構築します。
なお、メッシュのような3次元データをDeep Learningで扱うには幾つか手法がありますが、
今回は簡易的にジョイントの2次元位置を推定する目的のため、2次元のCNNを用いました。
それにあわせて入力データも、2次元データに変換する前処理(量子化)を施します。
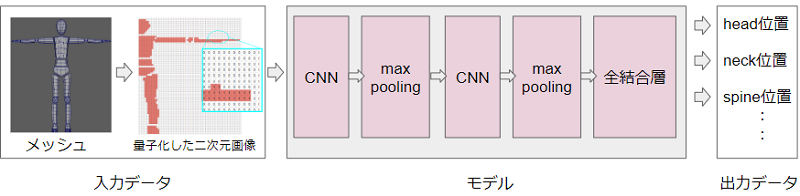
以上でモデルの構築は完成です。
ただし、モデルは構築しただけではうまく機能しません。
正しく機能させるためには、モデルを学習させる必要があります。
2. 教師データの作成
Deep Learningのモデルの学習方法は一般に、
「教師あり学習」「教師なし学習」「強化学習」に大別されます。
今回の目的のように、入力から正解を導きたい場合は「教師あり学習」でモデルを学習させます。
「教師あり学習」での学習には、教師データの準備が必要です。
教師データとは、入力データと、入力に対する出力データの正解のセットを指します。
たとえば、手書き数字の識別モデルにおける教師データは、
- 入力データ:「3」と書かれた手書き文字画像
- 正解データ:ラベル[3]
となります。
今回の目的の場合ですと、
- 入力データ:人体モデルのメッシュ
- 正解データ:各ジョイントの位置
となります。
通常、モデルの学習のためには、数千、数万という単位の教師データが必要です。
たとえば、一般に手書き数字の識別で用いられるMNISTという教師データには、
手書き数字画像と正解のラベルが7万セット含まれています。
そのような量のジョイントつき人体メッシュを用意することは現実的ではないため、
今回は検証用に作成した簡単な素体をもとにして、教師データを量産しました。
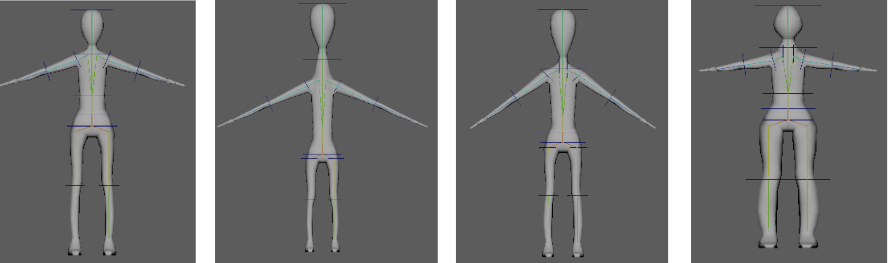
各ジョイントのトランスフォーム値をランダムに与えて、様々な体形・様々な姿勢のメッシュを生成すると、
- 入力データ:生成されたメッシュ
- 正解データ:各ジョイントの位置
という教師データのセットになります。
この教師データを1,000体分量産して、モデルを学習させました。
3. テストデータの検証
いよいよ今回のモデルでジョイント位置が推定できるか検証します。
テストデータとして、
Gugenka様『高崎柚乃』https://gugenka.jp/original/yuno-3d.php
©Gugenka® from CS-REPORTERS.INC/YUNO
をお借りしました。
実行結果はこちらです。
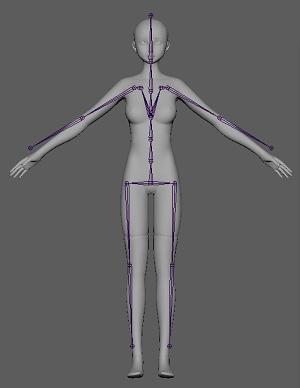
メッシュに対して、ジョイントが作成されました。
なんとなく体に沿わせることができています ……が、
正直精度としては全く使い物にならない……という結果ですね。
また、この図からは分かりませんが、奥行きが考慮されておらず、
Z方向は0に配置されているので、横から見ると当然ずれが生じています。
期待通りとはいかない部分も多い結果ではありましたが、
当時、検証した2次元のCNNを用いたモデルのご紹介は以上になります。
4. おわりに
今回は学生時代にDeep Learningを使って自動ジョイント配置に
挑戦した際のプロセスと結果をまとめました。
結果としては期待していた精度は得られませんでしたが、
その理由について、当時、以下のような要因があると考えました。
要因1.3次元データを無理やり2次元に圧縮している
データを2次元に圧縮したことにより、
多くの情報が抜け落ちていることは容易に推測できます。
3次元データのまま計算できるモデルを組み立てる方法を採用すべきかもしれません。
要因2.Deep Learningのモデル設計が不適切
今回は単純にCNN層とmax pooling層を2回重ねた単純なモデルで検証を行いましたが、
これだけでは十分に身体の各部位の特徴が抽出できなかったと思われます。
層の増加やパラメータの調整で改善する余地があるかもしれませんし、
より複雑な層を導入すべきかもしれません。
要因3.教師データ数や種類の不備、または不足
今回教師データとして使用した単純なメッシュでは、
身体の各部位があいまいにしか表現されていませんでした。
より量産に適した精密なメッシュ作成すると異なる結果が出るはずです。
また教師データの数として、1,000体では少なすぎた可能性もあります。
このように振り返りはしましたが、
当時は独学での学習だったこともあり類似のモデルを探ることもできず、
妥当な振り返りと言えるかどうか、なかなか検証する機会がありませんでした。
ところが昨年のSIGGRAPH2020で、”RigNet”(https://zhan-xu.github.io/rig-net/)
というマサチューセッツ大学の研究が発表されました。
こちらのモデルもメッシュからジョイント位置を自動推定する
機能を目的として作成されており、さらにスキニングまで行うことができます。
このモデルと当時の自身のモデルを比較することで、振り返りの妥当性を検証できそうです。
論文によると、3D座標上の頂点からジョイント位置を推定する際、
GMEdgeNetと名付けられたネットワークを用いているようです。
このネットワークの中では、GMEdgeConvと名付けられた畳み込み層が使用されていて、
隣接する頂点を畳み込むことで3D空間上における特徴を抽出しているようです。
また、学習やテストのために2703ものリグ付きアセットを使用した、とも記載されています。
今回の自身の検証内容と比較すると、RigNetでは
- 3次元データが使用されている
- より複雑なモデルが使用されている
- より多くの学習データが使用されている
ということになります。
どうやら振り返りは妥当だった、と言えそうです。
今後、これらの点を改善することで、
より精度が向上する様子をお届けできるのではないか……と期待しています。
Deep Learningは決して簡単とは言えない部分も多いですが、
少しずつ理解して積み立てていけばゴールに近づいていく感覚があり、それはやはり楽しいですね。
まだまだ奮闘は続きそうですが、今後、より精度が向上する様子をお届けできればと思います。
ここまでお読みいただき、ありがとうございました!
※免責事項※
本記事内で公開している全ての情報について、その完全性、正確性、適用性、有用性等いかなる保証も行っておりません。
これらの情報のご利用により、何らかの不都合や損害が発生したとしても、当社は何らの責任を負うものではありません。
自己責任でご使用ください。